
こんにちは。趣味グラマのNobu(@nm_aru)です。
コロナの影響で本業があまりに忙しく、ブログを全く書けていませんでした…。
個人開発も完全にストップしており、そっち方面は全く書けないのですが、たまたま本業でスクレイピングする必要があったので、そこで困った事を備忘録として書いておこうと思います。
悲しいことに、DartとかFlutterの文法は忘れつつある…。
スクレイピングの基本はCSSセレクタを把握すること
スクレイピングするにあたって、まずは対象となるサイトのHTMLとCSSの解析を行います。
Google Chromeの開発者ツールを使えば、誰でも簡単に解析を行う事ができます。

そして、欲しい情報がみつかったら、その情報を囲んでいるタグのclassやidを確認します。
<div class="entry-content cf" itemprop="mainEntityOfPage">例えば、こんなタグの場合は「entry-content cf」の部分ですね。
これがidであれば、ページ内に1つしか無いので簡単ですが、classの場合は複数ある可能性があるので、その辺も考慮した上でスクレイピングを行います。
一覧ページなどの場合は、class指定で一覧全てを一気に取得できたりもするので、そう言った時はclassは便利です。
セレクタが謎の文字列であり、さらに変化する…
今回は、とあるサイトの情報が欲しいと言うことだったので、過去にRubyやPythonでいくつもスクレイピングしてきた自分としては、まぁ1時間もあればできるだろうなと思い、さくっとデータ取得して驚かせてやろうと思ってました。
さらに、今回はRubyやPythonでは無く、TypeScriptでpuppeteerを使ってみることで、新しい物も触れてラッキー的な、めっちゃ軽く考えて挑んでみると悲劇が…。

対象サイトをChromeの開発者ツールで見てみると、classに指定されているのは
<div class="ao bm fg">みたいな感じで、全く意味の無い文字で構成されています。
まぁ、この辺は難読化の一種なんだろうなと思い、スクレイピングのプログラムを作り、実行してみると、データが取れたり取れなかったり、安定しません。
何故だろうと、開発者ツールで再度HTMLを眺めていると、最初に見た時とclassの中身が変わっていることに気付きました。
難読化どころか、セレクタが何かの条件で動的に変わってしまうと言う恐ろしい仕様のサイトでした…。
classやidを使わずに、HTMLの構造で要素を指定する
classやidを使うと、HTMLの構造は気にせず、欲しい情報に一気に到達することができます。
しかし、今回の対象サイトはclassの中身が動的に変わってしまうため使用することができません。
この場合、原始的ではありますが、HTMLの構造を辿っていくことで要素にたどり着くことができます。
と言っても、自分でHTMLの構造を先頭から見るのは面倒くさいので、Chromeに助けてもらいます。
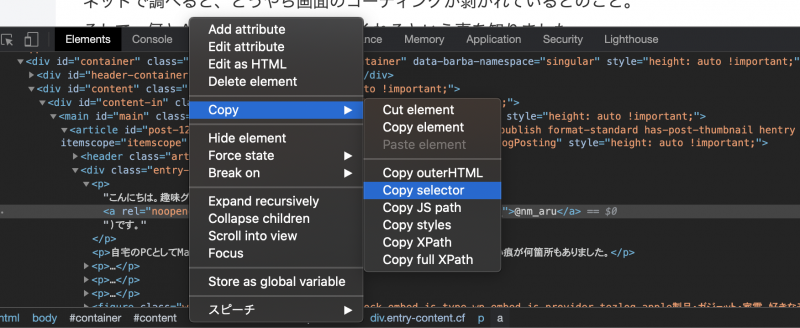
開発者ツールを使って目的の情報までのセレクタを取得します。
div > div.hoge > div#fuga > a例えば、こんな感じのセレクタが取れた場合、これをCSSの擬似クラスを使って、以下のような形に書き換えます。
div > div:nth-child(3) > div:first-child > aこうすれば、classが動的に変わろうとも、データを取得することができます。
ちなみに、この方法でやろうと思えたのは、動的セレクタのサイトをどうやったらスクレイピングできるのかを探していた時に、以下のサイトに出会ったからでした。

まとめ
セレクタが動的に変わるのは、データを取る側からすると厄介ですが、サイト側からすれば、せっかく集めたデータを簡単に持っていかれたくないと考えるのも分かるので、この辺はいたちごっこになるのかもですね。
とりあえず、データの取得はできたので一安心です。
早くFlutterアプリの開発に戻れるよう、まずは本業を頑張ろうと思います!

コメント